
早稲田大学 知覚情報システム・メディアインテリジェンス研究室
- English
- 日本語
大規模映像の意味索引付け技術(TRECVID)
大規模映像の意味索引付け技術(TRECVID)
インターネット上に存在する多種多様な映像に対し、自動解析を行い、動画のシーンに対して自動で意味索引付けを行う技術の高性能化に取り組んでいます。これにより、インターネットにアップロードされる莫大な映像からユーザが見たい映像を容易に検索できるだけでなく、悪意のあるユーザによる違法性/危険性の高い映像のアップロードを未然に抑止する等、様々なアプリケーションに活用できます。
米国国立標準技術研究所(NIST)が毎年実施しているTRECVIDベンチマークで用いられる大規模映像データを用いた実験により、「動物」「建物」「大人」「山」「電話」のような人やオブジェクト、「屋外」「夜間」「教室」のようなシーンに加え、「飛行機が飛んでいる」「人が踊っている」「人が泳いでいる」等の複雑な動作についても、大規模映像データベースから高精度に検出できることを確認しました。この開発した技術を元に、2015年のTRECVIDベンチマークの意味索引付けタスクに結果を提出したところ、参加した全29チーム中、2位の成績を収めることができました。
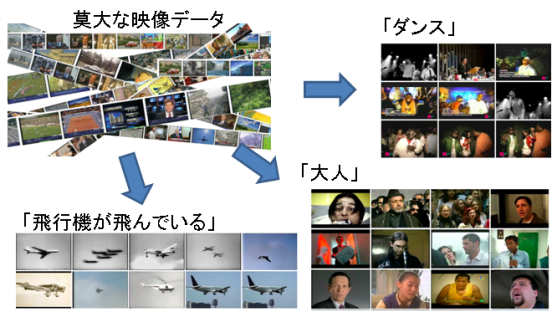
図:大規模映像の自動解析
Related Publications
- Kazuya Ueki, Tetsunori Kobayashi, “Video Semantic Indexing using Object Detector,” Proc. VRCAI2016, Dec. 2016. [Best Poster Award]
- Kazuya Ueki, Kotaro Kikuchi, Susumu Saito, Tetsunori Kobayashi, “Waseda at TRECVID 2016: Ad-hoc video search,”Notebook paper of the TRECVID 2016 workshop, Nov. 2016. [First place at Ad-hoc video search task]
- Kazuya Ueki, Tetsunori Kobayashi, “Image retrieval under very noisy annotations,” Proc. EUSIPCO2016, pp.1277-1282, Aug. 2016.
- Kotaro Kikuchi, Kazuya Ueki, Tetsuji Ogawa, Tetsunori Kobayashi, “Video semantic indexing using object detection derived features,” Proc. EUSIPCO2016, pp.1288-1292, Aug. 2016.
- Kazuya Ueki and Tetsunori Kobayashi, “Waseda at TRECVID 2015: Semantix Indexing,” Proc. of TRECVID 2015, 2015.
Projects
OTHER SITES



© 2015 Perceptual Computing Group, Waseda University. All Rights Reserved