
早稲田大学 知覚情報システム・メディアインテリジェンス研究室
- English
- 日本語
WWWを用いた語彙情報の収集・共有・管理システム
WWWを用いた語彙情報の収集・共有・管理システム
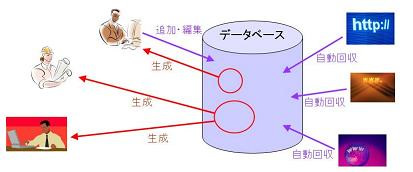
今日の音声認識システムは、入力された音声を”読み”として認識して単語に変換しているのではなく、あらかじめ登録された”語彙”から、入力された音声データに最も近い”語”を選択するように作られています。そのために、音声認識アプリケーションでは、アプリケーション毎の語彙情報の定義が必須であり、その定義はアプリケーションの品質に大きな影響を与えます。しかしながら、語彙情報の定義はアプリケーション毎に人手で行われるのが一般的であり、日々増加する新規語彙への対応や、標準的な語彙を考慮に入れたユーザビリティの高い語彙情報の設計は非常に困難な作業になります。
本研究ではその負荷を軽減するために、ウェブ上に散在する言語資源を自動的に収集し、音声認識アプリケーション開発者による語彙情報の定義の効率化と高品質化を可能にするウェブシステムを開発しています。
Projects
OTHER SITES



© 2015 Perceptual Computing Group, Waseda University. All Rights Reserved